We needed a Python interpreter that can be shipped everywhere. You won’t believe what happened next!
![Snakes on a Data Plane]()
“When I said I wanted portable Python, this is NOT what I meant!”
In theory, Python is a portable language. You can write your script locally and distribute it to other machines with the Python interpreter. In practice, things can go wrong for a variety of reasons.
The first and simpler problem is the module system: for a script to run, all of the modules it uses must be installed. For Python-savvy users, installing them is not a problem. But for a software vendor that wants to guarantee a hassle-free experience for all sorts of users the module dependency is not always easily met.
Second, Python is not a language, but actually two languages: under the name Python, there are Python2 and Python3. And while Python2 is set to be deprecated soon (which has been a true statement for the past decade, btw!) and bleeding-edge organizations will deal with that nicely, the situation is much different in old-school enterprise: RHEL7, for instance, does not ship with a Python3 interpreter at all and will still be supported under Red Hat policies for years to come.
Using Python3 in such distributions is possible: third-party organizations like EPEL produce RHEL-compatible binaries for the interpreter. But once more, old-school enterprise usually means security policies are in place that either disallow installing packages from untrusted sources, or want to install the Python scripts in machines with no connection to the internet. EPEL would require internet connectivity to update dependencies if some packages are some minor versions behind, which makes this a no go.
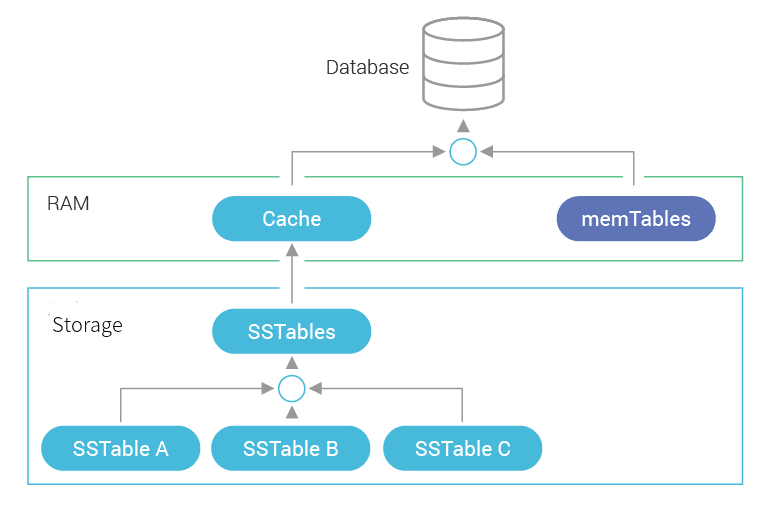
Scylla is the Real Time Big Data Database. In organizations with strict security policies, the database nodes tend to be even stricter than average. While our main database codebase is written in native C++, we adopt higher level languages like Python for our configuration and deployment scripts. In dealing with enterprise-grade organizations, we have dealt with the problem on how to ship our Python scripts to our customers in a way that will work across a wide variety of setups and security policies.
![Harry Potter, a Python Interpreter]()
One of many approaches to a Python interpreter. Requires broomstick package for portability.
We considered many approaches: should we just rewrite everything in C++? Should we make sure that everything we do works with Python2 as well, and uses as few modules as possible? Should we compile the Python binaries to C with Cython or Nuitka? Should we rely on virtualenv or PyInstaller to ship a complete environment? All of those solutions had pros and cons and ultimately none of them would work across the wide variety of scenarios our database seeks to be installed.
In this article we will very briefly discuss those alternatives, and describe in details the solution we ended up employing: we now distribute a full Python3 interpreter together with our scripts, that can be executed in any Linux distribution of any kind.
“Why not X?” Or, The Top Three Reasons We Didn’t Use Your Pet Suggestion!
![Ophidiophobia or Fear of Snakes; courtesy SantiMB.Photos]()
Image courtesy SantiMB.Photos; used with permission
Computer science is hard. While cosmologists tackle hard questions like “where do we come from?”, anyone working with code has to deal with much harder questions like “why didn’t you use X instead?”, where X is any other approach that the reader has in mind. So let’s get that out of the way and discuss the alternatives!
1. Rewrite our scripts
ScyllaDB is an Open Source database mainly written in C++. Since we already have to deploy our C++ code in a portable manner, it wouldn’t be a stretch to just rewrite the Python scripts. We know what you are thinking and sure, we could also have rewritten it in Go, Lua, Rust, Bash, Fortran or Cobol.
However, we wrote those scripts in Python initially for a reason: configuration and deployment are not performance critical, and writing that kind of code in Python is easy, and it is a language that is well known among many developers from many backgrounds.
Rewriting something that already does its job just fine is even worse, since this is time we could be spending somewhere else. Not a chance.
2. Write everything to also work with Python2
This would be like coding with shackles: many modules that we already use are not even available for Python2 anymore and soon the entire Python2 language will be no more. We would rather be free to code as we will, without having to worry about that. Making sure that changes to the scripts don’t break that also require testing infrastructure (we still use human coders, the kind that every now and then forgets something).
3. Just compile it with Nuitka, Cython, use PyInstaller, or whatever!
This is where things get interesting: we did very seriously consider those alternatives. The problem is that all of them will generate some standalone installer that ships with its dependencies. But such installer cannot be shipped everywhere.
Let’s take a look for instance at what cython generates. Consider the following script:
We can tell cython to compile it with the environment embedded into a single binary, and in theory that’s what we would want: we could then distribute the resulting binary. But how does it look like in the end? Cython allows us to compile the python script and generate an ELF executable binary in the end:
ELF binaries in Linux can consume shared libraries in two ways: they can be loaded at the program startup time, or dynamically loaded during its execution. The ldd tool can be used to inspect which libraries the program will need during startup. Let’s see what the cython-generated binary generates:
There are two problems with the output above. First, the list is deceptively small. Since hello uses the YAML library, we would expect it to depend on it. The strace utility can be used to inspect all calls to the Operating System being issued by a program. If we use this to see which files are being opened we can confirm our suspicion:
That is because libyaml is being loaded during execution time. Cython has no knowledge of which libraries will be loaded during execution time and will just trust that those are found in the system.
Another problem is that the resulting binary depends on system libraries from the host system (like the GNU libc, libpython, etc), on their specific versions. So while it can be transferred to a system similar to the host system, it can’t be transferred to an arbitrary system.
The situation with PyInstaller is a bit better. The shared libraries the script uses during execution time are discovered and added to the final bundle:
But we still have the issue that the resulting binary depends on the basic system libraries needed during startup, as the ldd program will tell us:
This is actually discussed in the PyInstaller FAQ, from which we quote the relevant part for simplicity (highlight is ours):
The executable that PyInstaller builds is not fully static, in that it still depends on the system libc. Under Linux, the ABI of GLIBC is backward compatible, but not forward compatible. So if you link against a newer GLIBC, you can’t run the resulting executable on an older system. The supplied binary bootloader should work with older GLIBC. However, the libpython.so and other dynamic libraries still depends on the newer GLIBC. The solution is to compile the Python interpreter with its modules (and also probably bootloader) on the oldest system you have around, so that it gets linked with the oldest version of GLIBC.
As the PyInstaller FAQ notices, a fully static binary (without using shared libraries at all) is usually one way to overcome shared library dependencies. However such method can present problems on its own, the most obvious of them being the final size of the application: if we ship 10 scripts, each script has to be compiled into its own multi-MB bundle separately. Soon, this solution becomes non-scalable.
The proposed solution, building it in the oldest available system also doesn’t quite work for our use case: the oldest available system is exactly the ones in which installing Python3 can be a challenge and tools are not up to date. We rely on modern tools to build, so often we want to do the other way around.
We tried Nuitka as well, which is an awesome project and can operate as a mixture between what cython and PyInstaller offers with its --standalone mode. While we won’t detail our efforts here for brevity, the end result has drawbacks similar to PyInstaller. On a side note, both these tools seem to have issues with syntax like __import__(“some-string”) (since it is not possible to know what will be imported until this is called during the program execution time), and modules may have to be passed explicitly in the command line in that case. You never know when a dependency-of-your-dependency may do that, so that’s an added risk for our deployments.
Virtualenv also has similar issues. It solves the module-packaging issue nicely, but it will still create symlinks to core Python functionality in the base system. It is just not intended for across-system portable deployments.
Taming the wild Python — Our solution:
![Animalist: Fear of Pythons]()
At this point in our exploration we realized that since our requirements look a bit unique, then maybe that means we should invest in our own solution. And while we could invest in enhancing some of the existing solutions (the reader will notice that some of the techniques we used could be used to solve some of the shortcomings of PyInstaller and Nuitka as well), we realized that for the same effort we could ship the entire Python interpreter in a way that it doesn’t depend on anything in the system and then just uses that to execute the scripts. This means not having to worry about any compatibility issue, every single Python syntax will work, there is no need to compile the scripts statically, or compile the code an lose access to the source in the destination machine.
We did that by creating a relocatable interpreter: in simple terms, the interpreter we ship will also ship with all the libraries that we need in relative paths in the filesystem, and everything that is done by the interpreter will refer to those paths. This is similar to what PyInstaller does, with the exception that we also handle glibc, the dynamic loader and the system libraries.
Another advantage of our solution is that if we package 30 scripts with PyInstaller, each of them will have its own bundle of libraries. This is because each resulting bundle will have its own copy of the interpreter and dependencies. In our solution, because we are relocating the interpreter, and all scripts will share that interpreter, all the needed libraries are naturally present only once.
What to include in the interpreter?
The code to generate the relocatable interpreter is now part of the Scylla git tree and is available under the AGPL as the rest of Scylla (although we would be open to move it to its own project under a more permissive license if there is community interest). It can be found in our github repository. The script is used to generate the relocatable interpreter works on any modern Fedora system (since we rely on Fedora tools to map dependencies). Although it has to be built on Fedora, it generates an archive that can be then copied anywhere to any distribution. We pass as an input to the script the list of modules we will use, for example:
We then use standard rpm management utilities (which is why the generation of the relocatable interpreter is confined to Fedora) in the distribution to obtain a list of all files that these modules need, together with its dependencies:
We then copy the resulting files, with some heuristic to skip things like documentation and configuration files, to a temporary location. We organize it so the binaries go to libexec/, and the libraries go to lib/.
At this point, the Python binary still refers to hard coded system library paths. People familiar with the low level inner workings of Linux shared objects will by now certainly think of the usual crude trick to get around this: setting the environment variable LD_LIBRARY_PATH, which tells the ELF loader to search for shared objects in an alternative path first.
The problem with that is that as an environment variable it will be inherited by child processes. Any call to an external program would try to find its libraries in that same path. So code like this:
output = subprocess.check_output(['ls'])
wouldn’t work, since the system’s `ls` needs to use its own shared libraries, not the ones we ship with the Python interpreter.
A better approach is to patch the interpreter binary so as not to depend on environment variables. The ELF format specifies that lookup directories can be specified in the DT_RUNPATH or DT_RPATH dynamic section attributes. And this being 2019, thankfully we have an app for that. The patchelf utility can be used to add that attribute to an existing binary where there was none, so that’s our next step ($ORIGIN is an internal variable in the ELF loader that refers to the directory where the application binary lives)
patchelf --set-rpath $ORIGIN/../lib <python_binary>
Things are starting to take shape: now all the libraries will be taken from ../lib and we can move things around. This works with both libraries loaded at startup and execution time. The remaining problem is that the ELF loader itself has to be replaced as in practice it has to match the libc in use by the application (where the API to load shared libraries during execution time will live)
To solve that, we ship the ELF loader as well!. We place the ELF loader (here called ld.so) in libexec/, like the actual python binary, and Inside our bin/ directory, instead the Python binary itself we have a trampoline-like shell script that looks like this:
This shell script finds the real path of the executable, in case you are calling it from a symlink, (stored in “x”), and then splits it in its basename (“b”) and the root of the relocatable interpreter (“d”). Note that because the binary will be inside ./bin/, we need to descend one level from its dirname.
In the last two lines, once we find out the real location of the script (“d”), we find the location of the dynamic loader (ld.so) and the Python binary ($realexe) which we know will always be in libexec and force the invocation to happen using the ELF loader we provided, while setting PYTHONPATH in a way that make sure that the interpreter will find its dependencies. Does it work? Oh yes!
But how do we know it’s really taking its libraries from the right place? Well, aside from trying it on a old, target system, we can just look at the output of the ldd tool again. We installed an interpreter into /tmp//python/, and this is what it says:
All of them are coming from their relocatable location. Well, all except for ld-linux-x86_64.so.2, which is the ELF loader. But remember we will force the override of the ELF loader by executing ours explicitly, so we are fine here. The libraries loaded at execution time are fine as well:
And with that, we now have a Python interpreter that can be installed with no dependencies whatsoever, in any Linux distribution!
But wait… no way this works with unmodified scripts
![OMG That's Not a Python!]()
“OMG! That’s not a Python!”
If you are thinking that there is no way this work with unmodified scripts, you are technically correct. The default shebang will point to /usr/bin/python3, and we still have to change every single script to point to the new location. But nothing else aside from that has to be changed. Still, is it even worth the trouble?
It is, if everything can happen automatically. We wrote a script that given a set of Python scripts, will modify their shebang to point to `/usr/bin/env python3`. The actual script is then replaced by a bash trampoline script much like the one we used for the interpreter itself. That guarantees that the relocatable interpreter precedes everything else in the PATH (so env ends up picking our interpreter, but without having to mess with the system’s PATH), and then calls the real script which now lives in the `./libexec`/ directory.
We set the PYTHONPATH as well to make sure we’re looking for imports inside libexec, to allow local imports to keep working. See for instance what happens with scylla_blocktune.py, one of the scripts we ship, after relocating it like this:
And there we have it: now we can distribute the entire directory /tmp/test with as many Python3 scripts as we want and unpack it anywhere we want: they will all run using the interpreter that ships inside it, that in turn can run in any Linux distribution. Total Python freedom!
But how extensible is it really??
![Fully Extensible Python]() An example of fully extensible Python
An example of fully extensible Python
For people used to very flexible Python environments with user modules installed via pip, our method of specifying the specific modules we want installed in the relocatable package doesn’t seem very flexible and extensible. But what if instead of packaging those modules, we were to package pip itself?
To demonstrate that, we ran our script again with the following invocation:
Note that since the pip binary in the base system is itself a python script, we have to modify it as well before we copy it to the destination environment. Once we unpack it, the environment is now ready. PyYAML was not included in the modules list and is not available, so our previous `hello.py` example won’t work:
But once we install it via pip, will we be luckier?
Where did it go? We can see that it is now installed in a relative path inside our relocatable directory:
Which due to the way the interpreter is started through the trampoline scripts, is included in the search path:
And now what? Just run it!
Conclusion
In this article we have detailed the uncommon ScyllaDB’s approach for a common problem: how to distribute software, in particular ones written in Python without having to worry about the destination environment. We did that by shipping a relocatable interpreter, that has everything it needs in its relative paths and can be passed around without depending on the system libraries. The scripts can then just be executed with that interpreter with just a minor indirection.
The core of the solution we have adopted could have been used with other third party tools like PyInstaller and Nuitka as well. But in our analysis at that point it would just be simpler to provide the entire Python interpreter and its environment. It makes for a more robust solution (such as easier handling on execution time dependencies) without restricting access to the source code, and is fully extensible: we demonstrated that it is even possible to run pip in the destination environment and from there install whatever one needs.
Since we believe the full depth of this solution is very specific to our needs, we wrote this in a way that plays well with our build system and stopped there. In particular, we only support creating the relocatable interpreter on Fedora. Extending the script to also support Ubuntu would not be very hard, though. The relocatable interpreter is also part of the Scylla repository and not a standalone solution at the moment. If you think we’re wrong in our analysis about this being a narrow and specialized use case and could benefit from this too, we would love to hear from you. We are certainly open to making changes to accommodate the wider needs of the community. Reach out to us on Twitter, @ScyllaDB, or drop us a message via our web site.
No actual Pythons were harmed in the writing of this blog.
The post The Complex Path for a Simple Portable Python Interpreter, or Snakes on a Data Plane appeared first on ScyllaDB.












 An example of fully extensible Python
An example of fully extensible Python











 “Now, here, you see, it takes all the running you can do, to keep in the same place. If you want to get somewhere else, you must run at least twice as fast as that!” — The Red Queen to Alice, Alice Through the Looking Glass
“Now, here, you see, it takes all the running you can do, to keep in the same place. If you want to get somewhere else, you must run at least twice as fast as that!” — The Red Queen to Alice, Alice Through the Looking Glass